Tutorial Overview¶
This tutorial is designed for the “Cloud Computing and Open-Source Scientific Software for Cryosphere Communities” Learning Workshop at the 2023 AGU Fall Meeting.
This notebook demonstrates how to search for, access, and work with a cloud-hosted NASA dataset using the earthaccess package. Data in the “NASA Earthdata Cloud” are stored in Amazon Web Services (AWS) Simple Storage Service (S3) Buckets. Direct Access is an efficient way to work with data stored in an S3 Bucket using an Amazon Compute Cloud (EC2) instance. Cloud-hosted granules can be opened and loaded into memory without the need to download them first. This allows you take advantage of the scalability and power of cloud computing.
We use earthaccess, a package developed by Luis Lopez (NSIDC developer) to allow easy search of the NASA Common Metadata Repository (CMR) and download of NASA data collections. It can be used for programmatic search and access for both DAAC-hosted and cloud-hosted data. It manages authenticating using Earthdata Login credentials which are then used to obtain the S3 tokens that are needed for S3 direct access. earthaccess can be used to find and access both DAAC-hosted and cloud-hosted data in just three lines of code. See https://
As an example data collection, we use ICESat-2 Land Ice Height (ATL06) granules over the Juneau Icefield, AK, for March and April 2020. ICESat-2 data granules, including ATL06, are stored in HDF5 format. We demonstrate how to open an HDF5 granule and access data variables using xarray. Land Ice Heights are then plotted using hvplot.
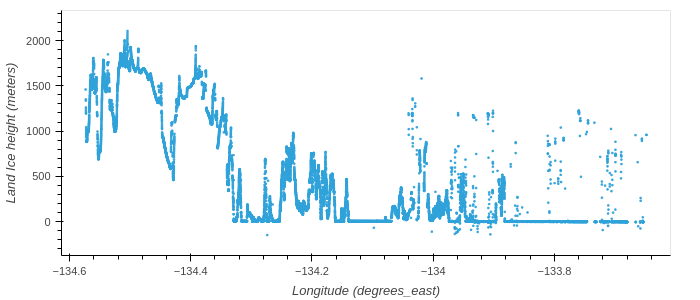
ATL06 Land Ice Heights for the margin of the Juneau Ice Field
Learning Objectives¶
In this tutorial you will learn:
- how to use
earthaccessto search for (ICESat-2) data using spatial and temporal filters and explore the search results; - how to open data granules using direct access to the appropriate S3 bucket;
- how to load an HDF5 group into an
xarray.Dataset; - how visualize the land ice heights using
hvplot.
Prerequisites¶
The workflow described in this tutorial forms the initial steps of an Analysis in Place workflow that would be run on a AWS cloud compute resource. You will need:
- a JupyterHub, such as CryoHub, or AWS EC2 instance in the us-west-2 region.
- a NASA Earthdata Login. If you need to register for an Earthdata Login see the Getting an Earthdata Login section of the ICESat-2 Hackweek 2023 Jupyter Book.
- A
.netrcfile, that contains your Earthdata Login credentials, in your home directory. See Configure Programmatic Access to NASA Servers to create a.netrcfile.
Credits¶
This notebook is based on an NSIDC Data Tutorial originally created by Luis Lopez, NSIDC, and Mikala Beig, NSIDC, modified by Andy Barrett, NSIDC, Jennifer Roebuck, NSIDC, Amy Steiker, NSIDC, and Jessica Scheick, Univ. of New Hampshire.
Computing Environment¶
The tutorial uses python and requires the following packages:
earthaccess, which enables Earthdata Login authentication and retrieves AWS credentials; enables collection and granule searches; and S3 access;xarray, used to load N-dimensional data with labeled axes;hvplot, used to visualize land ice height data.
We are going to import the whole earthaccess package.
We will also import the whole xarray package but use a standard short name xr, using the import <package> as <short_name> syntax. We could use anything for a short name but xr is an accepted standard that most xarray users are familiar with.
xarray is a powerful library for working with multi-dimensional data using labeled indices (analogous to Pandas for tabular data). It is leverages numpy, pandas, matplotlib and dask to build Dataset and DataArray objects with built-in methods to subset, analyze, interpolate, and plot multi-dimensional data. It makes working with multi-dimensional data cubes efficient and fun. A few great tutorials for learning Xarray are here and here.
We only need the xarray module from hvplot so we import that using the import <package>.<module> syntax.
# For searching and accessing NASA data
import earthaccess
# For reading data, analysis and plotting
import xarray as xr
import hvplot.xarray
import pprint # For nice printing of python objectsAuthenticate¶
The first step is to get the correct authentication to access cloud-hosted ICESat-2 data. This is all done through Earthdata Login. The login method also gets the correct AWS credentials.
Login requires your Earthdata Login username and password. The login method will automatically search for these credentials as environment variables or in a .netrc file, and if those aren’t available it will prompt you to enter your username and password. We use the prompt strategy here. A .netrc file is a text file located in our home directory that contains login information for remote machines. If you don’t have a .netrc file, login will create one for you if you use persist=True.
earthaccess.login(strategy='interactive', persist=True)auth = earthaccess.login()Search for ICESat-2 Collections¶
earthaccess leverages the Common Metadata Repository (CMR) API to search for collections and granules. Earthdata Search also uses the CMR API.
We can use the search_datasets method to search for ICESat-2 collections by setting keyword="ICESat-2". The argument passed to keyword can be any string and can include wildcard characters ? or *.
A count of the number of data collections (Datasets) found is given.
query = earthaccess.search_datasets(
keyword="ICESat-2",
)In this case, there are 89 datasets that have the keyword ICESat-2.
search_datasets returns a python list of DataCollection objects. We can view metadata for each collection in long form by passing a DataCollection object to print or as a summary using the summary method for the DataCollection object. Here, I use the pprint function to Pretty Print each object.
for collection in query[:10]:
pprint.pprint(collection.summary(), sort_dicts=True, indent=4)
print('') # Add a space between collections for readabilityFor each collection, summary returns a subset of fields from the collection metadata and Unified Metadata Model (UMM) entry.
concept-idis an unique identifier for the collection that is composed of a alphanumeric code and the provider-id for the DAAC.short-nameis the name of the dataset that appears on the dataset set landing page. For ICESat-2,ShortNamesare generally how different products are referred to.versionis the version of each collection.file-typegives information about the file format of the collection files.get-datais a collection of URLs that can be used to access data, dataset landing pages, and tools.
For cloud-hosted data, there is additional information about the location of the S3 bucket that holds the data and where to get credentials to access the S3 buckets. In general, you don’t need to worry about this information because earthaccess handles S3 credentials for you. Nevertheless it may be useful for troubleshooting.
For the ICESat-2 search results the concept-id is NSIDC_ECS or NSIDC_CPRD. NSIDC_ECS is for collections archived at the NSIDC DAAC and NSIDC_CPRD is for the cloud-hosted collections.
For ICESat-2 short-name refers to the following products.
| ShortName | Product Description |
|---|---|
| ATL03 | ATLAS/ICESat-2 L2A Global Geolocated Photon Data |
| ATL06 | ATLAS/ICESat-2 L3A Land Ice Height |
| ATL07 | ATLAS/ICESat-2 L3A Sea Ice Height |
| ATL08 | ATLAS/ICESat-2 L3A Land and Vegetation Height |
| ATL09 | ATLAS/ICESat-2 L3A Calibrated Backscatter Profiles and Atmospheric Layer Characteristics |
| ATL10 | ATLAS/ICESat-2 L3A Sea Ice Freeboard |
| ATL11 | ATLAS/ICESat-2 L3B Slope-Corrected Land Ice Height Time Series |
| ATL12 | ATLAS/ICESat-2 L3A Ocean Surface Height |
| ATL13 | ATLAS/ICESat-2 L3A Along Track Inland Surface Water Data |
Search for cloud-hosted data¶
If you only want to search for data in the cloud, you can set cloud_hosted=True.
Query = earthaccess.search_datasets(
keyword = 'ICESat-2',
cloud_hosted = True,
)
Search a data set using spatial and temporal filters¶
Once, you have identified the dataset you want to work with, you can use the search_data method to search a data set with spatial and temporal filters. As an example, we’ll search for ATL06 granules over the Juneau Icefield, AK, for March and April 2020.
Either concept-id or short-name can be used to search for granules from a particular dataset. If you use short-name you also need to set version. If you use concept-id, this is all that is required because concept-id is unique.
The temporal range is identified with standard date strings. Latitude-longitude corners of a bounding box are specified as lower left, upper right. Polygons and points, as well as shapefiles can also be specified.
This will display the number of granules that match our search.
results = earthaccess.search_data(
short_name = 'ATL06',
version = '006',
cloud_hosted = True,
bounding_box = (-134.7,58.9,-133.9,59.2),
temporal = ('2020-03-01','2020-04-30'),
count = 100
)We’ll get metadata for these 4 granules and display it. The rendered metadata shows a download link, granule size and two images of the data.
The download link is https and can be used download the granule to your local machine. This is similar to downloading DAAC-hosted data but in this case the data are coming from the Earthdata Cloud. For NASA data in the Earthdata Cloud, there is no charge to the user for egress from AWS Cloud servers. This is not the case for other data in the cloud.
[display(r) for r in results]Use Direct-Access to open, load and display data stored on S3¶
Direct-access to data from an S3 bucket is a two step process. First, the files are opened using the open method. This first step creates a Python file-like object that is used to load the data in the second step.
Authentication is required for this step. The auth object created at the start of the notebook is used to provide Earthdata Login authentication and AWS credentials “behind-the-scenes”. These credentials expire after one hour so the auth object must be executed within that time window prior to these next steps.
In this example, data are loaded into an xarray.Dataset. Data could be read into numpy arrays or a pandas.Dataframe. However, each granule would have to be read using a package that reads HDF5 granules such as h5py. xarray does this all under-the-hood in a single line but only for a single group in the HDF5 granule, in this case land ice heights for the gt1l beam*.
*ICESat-2 measures photon returns from 3 beam pairs numbered 1, 2 and 3 that each consist of a left and a right beam
%time
files = earthaccess.open(results)
ds = xr.open_dataset(files[1], group='/gt1l/land_ice_segments')dshvplot is an interactive plotting tool that is useful for exploring data.
ds['h_li'].hvplot(kind='scatter', s=2)Additional resources¶
For general information about NSIDC DAAC data in the Earthdata Cloud:
FAQs About NSIDC DAAC’s Earthdata Cloud Migration
NASA Earthdata Cloud Data Access Guide
Additional tutorials and How Tos: