Learning Objective¶
In this tutorial you will learn how to:
- Discover cloud-hosted datasets using NASA Earthdata Search.
- Get AWS S3 credentials so you can access this data.
- Get the S3 links to data granules.
Prerequisites¶
- An Earthdata Login account. See the NASA Openscapes Cookbook “Authentication” guide for more information.
Overview¶
NASA Earthdata Search is a web-based tool to discover, filter, visualize and access all of NASA’s Earth science data, both in Earthdata Cloud and archived at the NASA DAACs. It is a useful first step in data discovery, especially if you are not sure what data is available for your research problem.
This tutorial is based on the NSIDC NASA Earthdata Cloud Access Guide and the “How do I find data using Earthdata Search?” guide in the NASA Earthdata Cookbook.
Searching for data and S3 links using Earthdata Search¶
Search for Data¶
Step 1. Go to https://
Step 2. Check the Available in Earthdata Cloud box in the Filter Collections side-bar on the left of the page (Box 1 on the screenshot below). The Matching Collections will appear in the results box. All datasets in Earthdata Cloud have a badge showing a cloud symbol and “Earthdata Cloud” next to them. To narrow the search, we will filter by datasets supported by NSIDC by typing “NSIDC” in the search box (Box 2 on the screen shot below). If you want, you could narrow the search further using spatial and temporal filters or any of the other filters in the filter collections box.
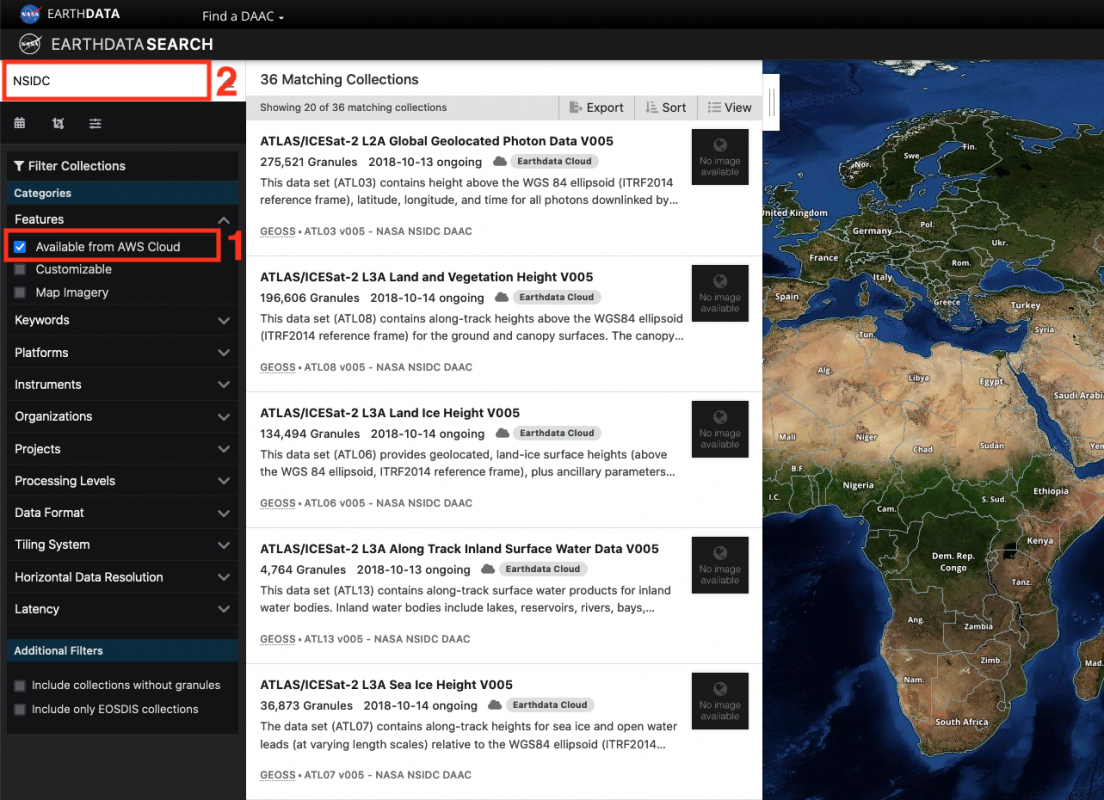
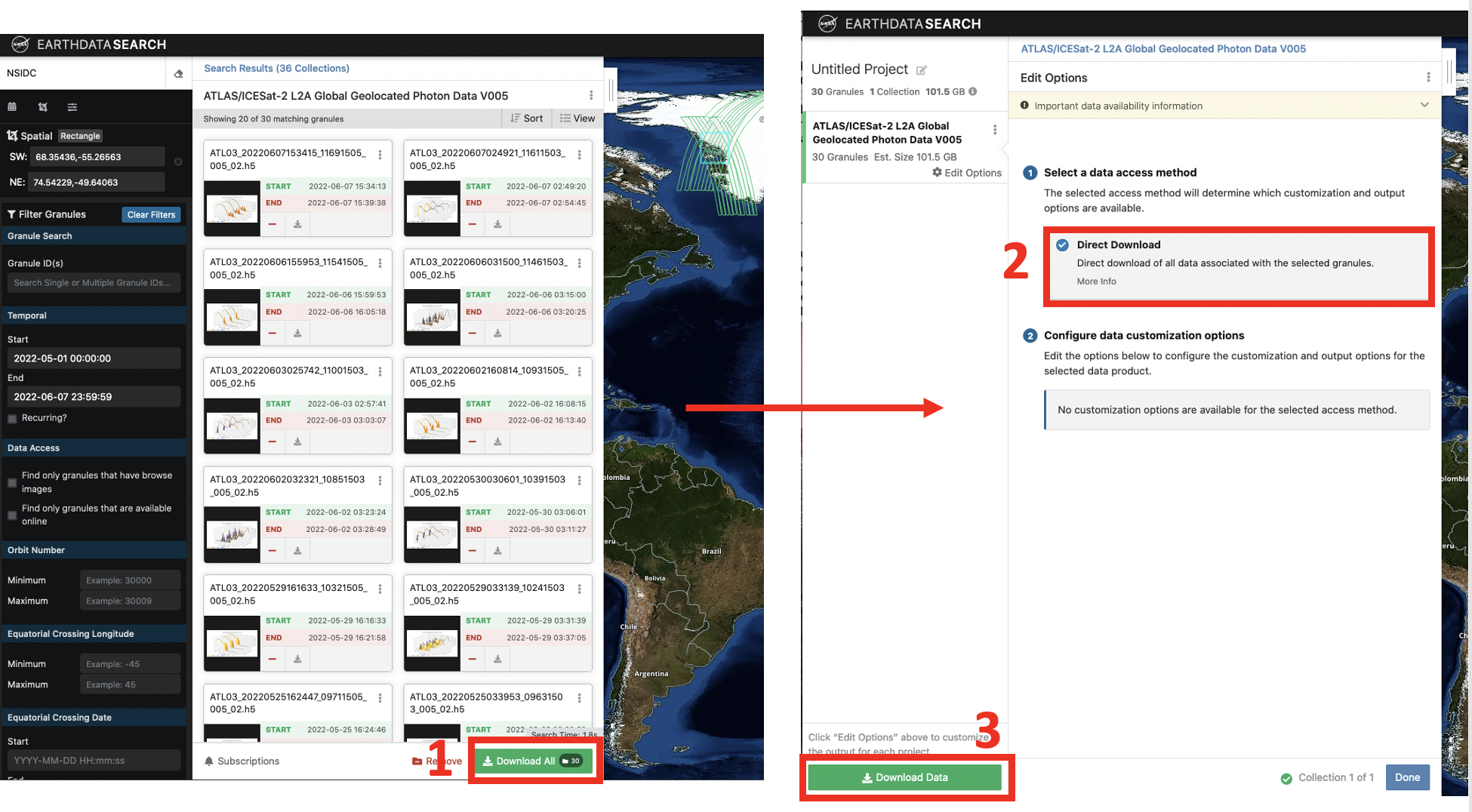
Step 3. You can now select the dataset you want by clicking on that dataset. The Search Results box now contains granules that match your search. The location of these granules is shown on the map. The search can be refined using spatial and temporal filters or you can select individual granules using the “+” symbol on each granule search result. Once you have the data you want, click the Download All (Box 1 in the screenshot below). In the sidebar that appears, select Direct Download (Box 2 in the screenshot below). Then select Download Data.
Getting S3 links and AWS S3 Credentials¶
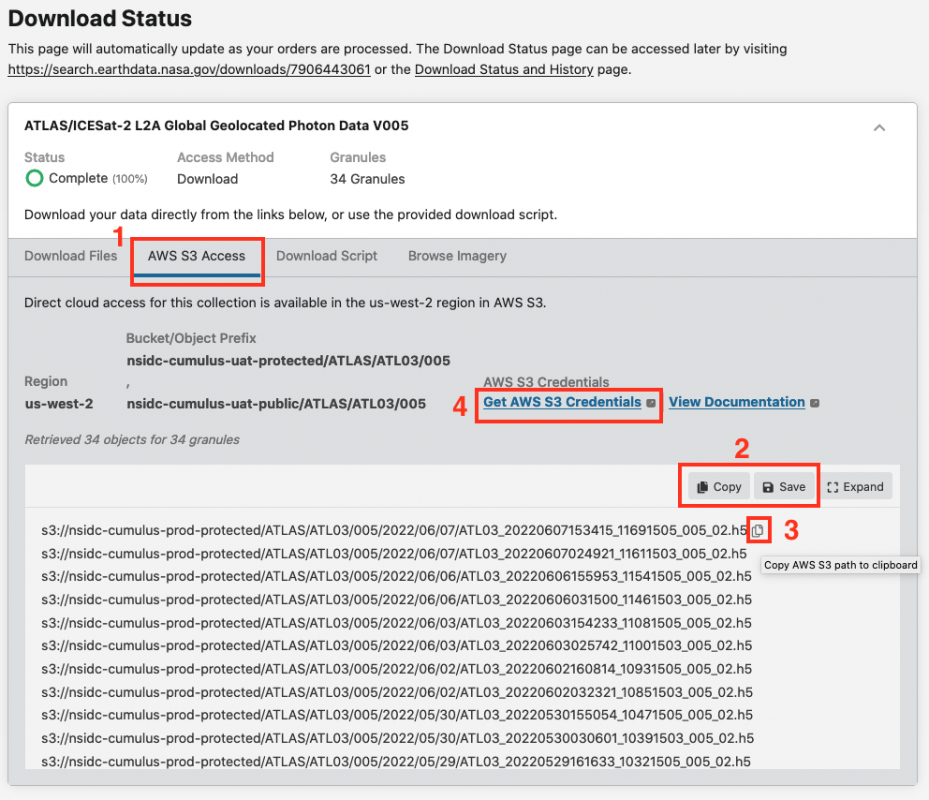
Step 4. A Download Status window will appear (this may take a short amount of time) similar to the one shown below. You will see a tab for AWS S3 Access (Box 1 in the screenshot below). Select this tab. A list of S3 links (urls) starting with s3:// will be in the box below. You can save them to a text file or copy them to your clipboard using the Save and Copy buttons (Box 2 in the screenshot below). Or you can copy each link separately by hovering over a link and clicking the clipboard icon (Box 3).
Step 5. To access data in Earthdata Cloud, you need AWS S3 credentials; “accessKeyId”, “secretAccessKey”, and “sessionToken”. These are temporary credentials that last for one hour. To get them click on the Get AWS S3 Credentials (Box 4 in the screenshot below). This will open a new page that contains the three credentials.
Using links and credentials from the command line¶
In the next earthaccess tutorial, we will work programmatically in the cloud to access datasets of interest. There are several ways to do this. One way to connect this web-based search part of the workflow to our next steps working in the cloud is to simply copy/paste the s3:// links provided in Step 3 above into a JupyterHub notebook or script in our cloud workspace, and continue the data analysis from there.
One could also copy/paste the s3:// links and save them in a text file, then open and read the text file in the notebook or script in the CryoCloud.